#* Enable Cross-origin Resource Sharing
#* @filter cors
# This is more complex than what's in the official documentation
# (https://www.rplumber.io/articles/security.html#cross-origin-resource-sharing-cors)
# because it correctly allows requests to come from http://localhost too
# (via https://github.com/rstudio/plumber/issues/66#issuecomment-418660334)
cors <- function(req, res) {
res$setHeader("Access-Control-Allow-Origin", "*")
if (req$REQUEST_METHOD == "OPTIONS") {
res$setHeader("Access-Control-Allow-Methods", "*")
res$setHeader("Access-Control-Allow-Headers", req$HTTP_ACCESS_CONTROL_REQUEST_HEADERS)
res$status <- 200
return(list())
} else {
plumber::forward()
}
}7 Annotations, error handling, and CORS
Before creating actual endpoints, we should add a little bit of additional infrastructure to the API first to make it easier to work with and allow it to be accessed from other computers.
7.1 Annotations and tags
The documentation page that opens when you first run the API is really convenient and I use it all the time. Currently, though, it’s a little boring and bereft of details. All the endpoints are categorized under a “default” heading, and the API description is literally “API Description”
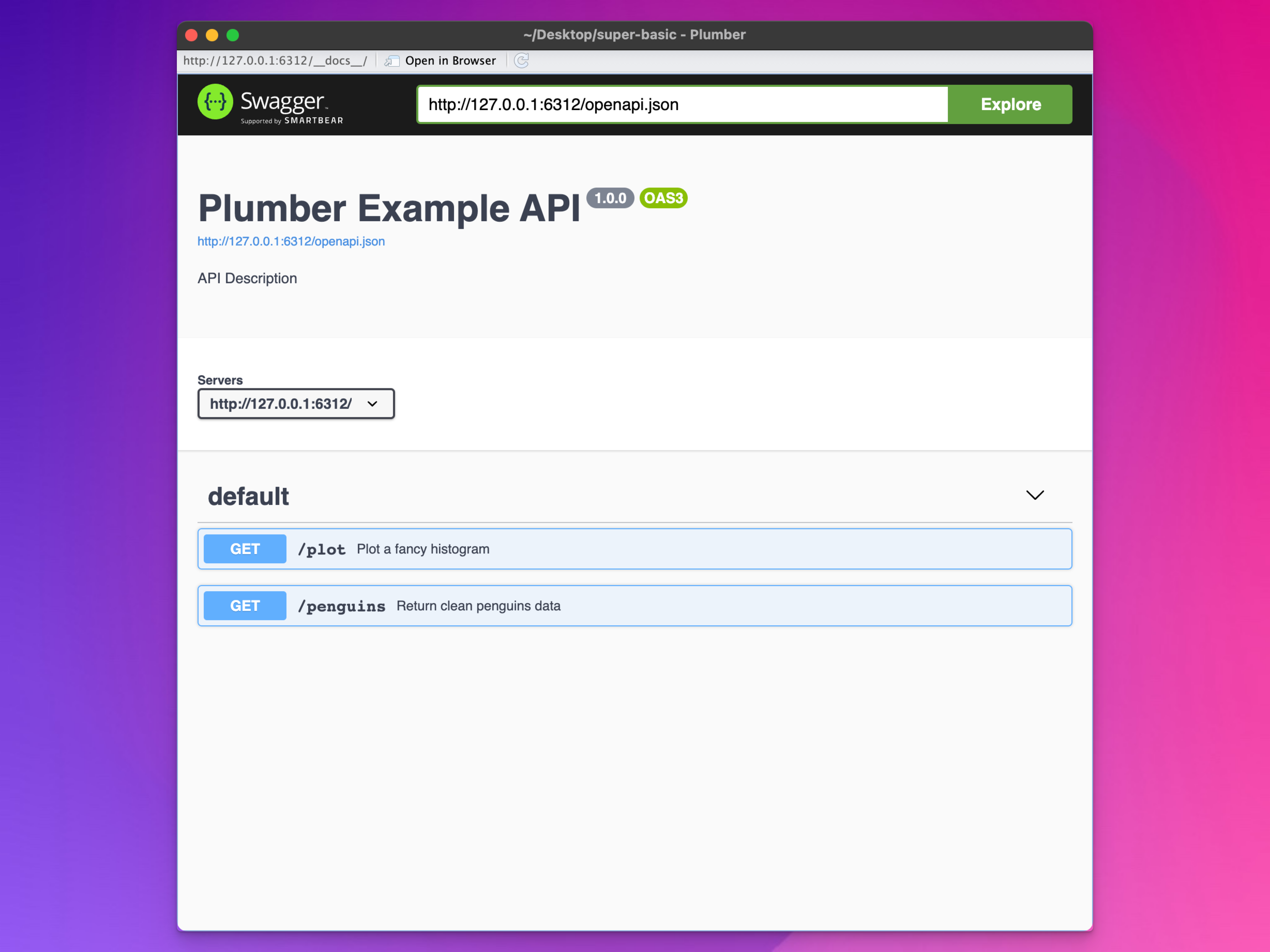
We can improve this documentation with annotations, or special comments that start with #* @.
7.1.1 Overall API details
We can control the overall API details with several possible global annotations. We’re already using one, like this:
#* @apiTitle Plumber Example APIWe can add some more too:
#* @apiTitle Plumber Example API
#* @apiDescription Fun times with R and plumber and APIs
#* @apiContact list(name = "Andrew Heiss", url = "https://www.andrewheiss.com/")
#* @apiLicense list(name = "MIT", url = "https://opensource.org/license/mit/")
#* @apiVersion 0.1.07.1.2 Details for specific endpoints
We can also use similar annotations for specific blocks or endpoints. We’ve already seen some with the API so far, like @serializer and @get here:
#* Return clean penguins data
#* @seralizer json
#* @get /penguins
function() {
# Stuff here
}In addition to more specific options like filters, response types, and so on, we can add tags or categories for endpoints so that they’re better organized in the documentation. To do this, we need to define two special annotations: (1) @apiTag for the overall category, and @tag to assign an endpoint to that category, like this:
#* @apiTitle Plumber Example API
#* @apiDescription Fun times with R and plumber and APIs
#* @apiContact list(name = "Andrew Heiss", url = "https://www.andrewheiss.com/")
#* @apiLicense list(name = "MIT", url = "https://opensource.org/license/mit/")
#* @apiVersion 0.1.0
#* @apiTag Data Access different data things
#* @apiTag Debugging Endpoints for testing to make sure things are working
#* Plot a fancy histogram
#* @tag Debugging
#* @serializer png list(width = 500, height = 300)
#* @get /plot
function(n = 100) {
# Stuff here
}
#* Return clean penguins data
#* @tag Data
#* @seralizer json
#* @get /penguins
function() {
# Stuff here
}7.1.3 Much nicer documentation
{plumber} parses all those annotations and creates a much nicer documentation page with better details and with endpoints nicely categorized:
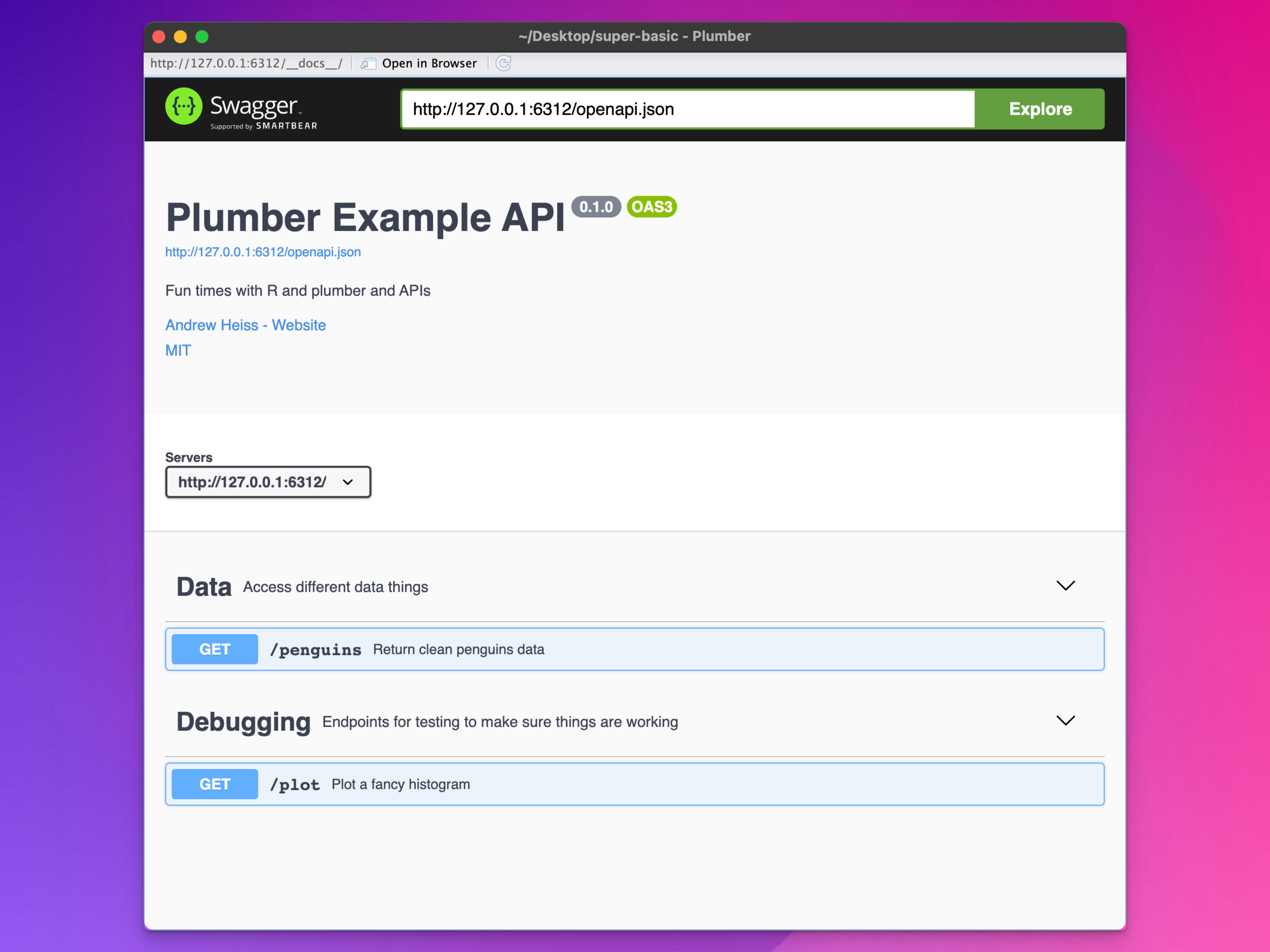
7.2 Error handling
In our histogram plotting function, we’ve added a little safeguard to make sure people don’t pass numbers that are too big:
if (n >= 10000) {
stop("`n` is too big. Use a number less than 10,000.")
}If you pass a huge number, you’ll get a JSON response like this:
{
"error": "500 - Internal server error",
"message": "Error in (function (n = 100) : `n` is too big. Use a number less than 10,000.\n"
}That’s nice, but the response code (500) is a little too generic. The HTTP protocol has a ton of more specific response codes. For instance, 200 means everything worked, while 404 means the response couldn’t be found (you’ve seen 404 errors in the wild all the time). Right now we’re returning a 500 response, which is a generic catch-all response to any kind of issue. In this case, passing a number that is too big actually fits one of the standard HTTP responses: it’s a bad request, which is code 400. It’d be nice if we could use that instead of the generic 500.
Also, the automatically generated message here is too messy. A user doesn’t know that something like function (n = 100) is happening behind the scenes. This message is actually revealing some of the R code to the user, which probably isn’t great. It would be nice to have a cleaner (and safer) message!
Fortunately Aaron Jacobs, currently a software engineer at Posit, has made a nice way to more gracefully handle these HTTP errors. See his post for all the details. For the sake of brevity, I’ll just show the final code here. We need to add all this:
# Custom error handling
# https://web.archive.org/web/20240110015732/https://unconj.ca/blog/structured-errors-in-plumber-apis.html
# Helper function to replace stop()
api_error <- function(message, status) {
err <- structure(
list(message = message, status = status),
class = c("api_error", "error", "condition")
)
signalCondition(err)
}
# General error handling function
error_handler <- function(req, res, err) {
if (!inherits(err, "api_error")) {
res$status <- 500
res$body <- jsonlite::toJSON(auto_unbox = TRUE, list(
status = 500,
message = "Internal server error."
))
res$setHeader("content-type", "application/json") # Make this JSON
# Print the internal error so we can see it from the server side. A more
# robust implementation would use proper logging.
print(err)
} else {
# We know that the message is intended to be user-facing.
res$status <- err$status
res$body <- jsonlite::toJSON(auto_unbox = TRUE, list(
status = err$status,
message = err$message
))
res$setHeader("content-type", "application/json") # Make this JSON
}
res
}
#* @plumber
function(pr) {
# Use custom error handler
pr %>% pr_set_error(error_handler)
}Now, go and change stop() in the histogram endpoint to api_error():
if (n >= 10000) {
api_error("`n` is too big. Use a number less than 10,000.", 400)
}Rerun the API and use the documentation page to pass a huge number to /plot. You’ll get a much nicer error now with 400 status code:
{
"status": 400,
"message": "`n` is too big. Use a number less than 10,000."
}7.3 CORS
Right now, for security reasons, the server that {plumber} creates will only allow people to access it from the same domain. Like, if I hosted the {plumber} server at api.example.com, I could create a website or dashboard at www.example.com and access the API from it just fine. But if I created a website at www.andrewheiss.com and made an Observable JS script that sent a request to api.example.com, it wouldn’t work. That’s a cross-domain request, and cross-origin resourse sharing (CORS) is disabled by default.
If you like that, cool—leave everything the way it is. Disallowing cross-origin resource sharing (CORS) is super common for APIs that you want to be more restricted.
But in this case, I want to be able to use the API from anywhere, including from local servers on my computer. When you render a Quarto document, for instance, it is served at http://localhost:SOME_PORT. If you’re accessing a {plumber} API online and it has CORS disabled, you won’t be able to use the API from your local document, since localhost is not the same domain as example.com.
The {plumber} documentation provides a short code snippet that adds a filter to allow CORS. However, it doesn’t work with localhost domains, since those are special. After lots of googling and experimenting, I found a more complete {plumber} filter for enabling CORS for all domains, including localhost URLs. Here it is:
Include that in plumber.R and you’ll have better CORS support.
7.4 Current plumber.R file
Here’s what the API is looking like now with our extra annotations, error handling, and CORS.